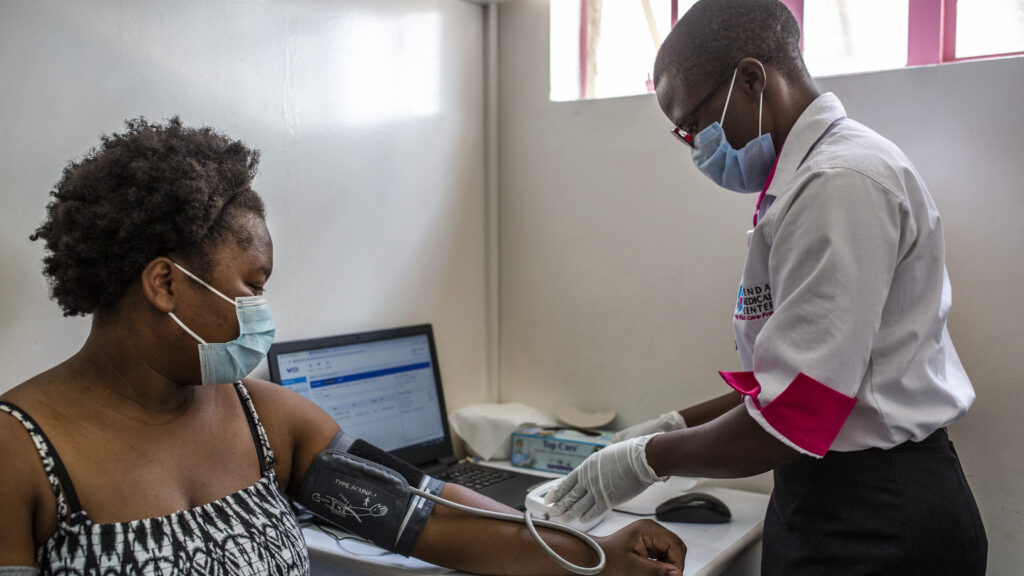
In a landmark study from Kenya by Penda Health and OpenAI, an artificial intelligence “safety net” called AI Consult reduced diagnostic errors by 16% and treatment errors by 13% across nearly 40,000 real-world patient visits. For a field saturated with hype, it’s a rare success that could avert more than 50,000 errors annually at just one clinic network.
Yet the study’s true importance is not that the algorithm worked but in the stark warning it provides: The hardest part of the AI revolution isn’t the code, but overcoming the immense human and systemic challenges required to deploy it safely.
Advertisement
The challenge of bridging the gap between a model and its implementation is not new. A 2005 analysis in The British Medical Journal, for instance, provided a durable blueprint, showing that decision support systems worked best when they were automatic and integrated into clinician workflow. Penda’s hard-won success two decades later is a powerful reminder that these foundational principles are more critical than ever.
While this study took place in the Kenyan capital of Nairobi, its findings are a direct warning to U.S. health systems. In a compelling example of reverse innovation, the lessons learned from this deployment provide an essential playbook for institutions like Mayo Clinic, with its multibillion-dollar Google AI partnership, and Geisinger, a leader in using predictive models to flag high-risk patients. The research reveals a critical bottleneck for the entire field of medical AI: the model-implementation gap. This chasm between a correct algorithm and the messy reality of clinical practice forces us to confront not only life-or-death stakes but the profound threat of codifying our biases into the tools meant to save us.
The study tracked 39,849 patient visits across 15 primary care clinics in Nairobi over three months. Half of the clinicians had access to AI Consult, a digital safety net that works like a co-pilot, continuously monitoring every patient interaction for potential errors. When clinicians miss vital signs, prescribe inappropriate medications, or make diagnostic mistakes, the system intervenes with color-coded alerts: green for no issues, yellow for advisory warnings, and red for critical safety concerns that require immediate attention. The AI was built using GPT-4o with extensive prompt engineering that incorporated Kenyan clinical guidelines and local medical protocols to avoid perpetuating historical biases in care, rather than specialized training data.
Advertisement
Independent physician reviewers then evaluated visit documentation to identify clinical errors across four categories — history-taking, investigations, diagnosis, and treatment — ranging from missing vital signs to inappropriate medications. Yet the study’s most sobering findings emerged from its patient safety reports, which documented two deaths that occurred during the trial period.
The authors judged that both deaths reviewed were “potentially preventable with correct AI Consult use.” In one case, involving a young adult with chest pain and tachycardia, the tool correctly “flagged multiple red alerts” that, if seen and followed, might have prevented the lapse. In the other, involving an infant with low oxygen saturation, the AI also produced the correct alerts, but the study notes it is “unclear whether these alerts were acknowledged or seen by the clinician” early in the rollout. The algorithm provided the right warnings, but this was not enough to save the patients.
Bridging the implementation gap comes at a steep price, not in software, but in people and time. The AI’s success wasn’t built on a one-time installation but on continuous, resource-intensive human effort. Penda’s managers had to coach clinicians, monitor data, and track a “left in red” metric — the percentage of critical safety alerts from the AI safety net that clinicians ignored. Initially, more than 35% of these warnings went unheeded, requiring intensive management intervention. This represents a massive operational expense rarely featured in the glossy marketing for enterprise AI. This proves the initial cost of a tool is merely a down payment on a much larger investment in change management.
The study reveals that the tool’s benefits required an investment of clinician time. Electronic medical record data showed that clinicians in the AI group had a median attending time of 16.43 minutes, compared with 13.01 minutes for the non-AI group. The researchers suggest this increased time was spent by clinicians responding to AI Consult feedback to improve quality. Crucially, the study also found that even when controlling for visit duration, AI group clinicians made fewer errors, suggesting the tool makes time spent more effective. The paper frames this as a “quality-time tradeoff” in the design of AI tools that requires further study.
Advertisement
The messy reality of clinical practice creates another challenge that goes beyond workflow integration. Health data is rife with systemic biases. When AI models are trained on this historical data, they don’t just learn medicine; they learn our ingrained patterns of care, including our flaws. This has led to real-world harm in the U.S., from a widely used algorithm that systematically underestimated the health needs of Black patients to models trained on male-centric data that fail to recognize heart attack symptoms in women. An AI trained on the subjective spectrum of past care doesn’t just become biased; it becomes a mechanism for scaling and entrenching those biases under a veneer of technological objectivity.
This is precisely the danger the Penda team consciously designed their tool to avoid. By choosing not to train their AI on potentially flawed clinical history and instead building it on a foundation of evidence-based guidelines, they provide a powerful template for building equitable AI. Their approach shows how to design tools that guide clinicians toward a better standard of care, rather than simply not reinforcing the statistical average of the old one.
The study is cause for genuine optimism, but not complacency. It suggests AI can be an empowering copilot for clinicians but also provides a clear mandate for a new standard of care for its deployment. The authors conclude that success requires three pillars: a capable model, clinically aligned implementation, and active deployment. To date, the industry has focused almost exclusively on the first.
In the U.S., the Food and Drug Administration has also focused on the model itself, validating the technical safety of algorithms. This is a critical foundation. But as the Penda study makes devastatingly clear, a safe algorithm is not the same as a safe system of care. What’s missing is a mandate for a formal “implementation and ethics playbook.”
The implications of this extend directly to the health AI market and its investors. For venture capitalists and health system innovation funds, the study is a clear warning: A company’s success will be determined less by the elegance of its algorithm and more by its strategy and budget for on-the-ground implementation. Due diligence must now shift from validating code to interrogating the costly, human-intensive work of clinical change management. For electronic health record giants like Epic, which are embedding AI co-pilots across their platforms, the lesson is that integration is not the same as implementation. Without a robust plan to manage workflow changes and ensure that AI-generated advice is actually followed, they risk selling expensive tools that create more alert fatigue and liability than clinical value.
Advertisement
It is crucial to highlight a limitation the researchers were transparent about: While the AI reduced clinical errors, they found no statistically significant difference in patient-reported outcomes between the two groups. This reveals a critical gap for the health AI industry, proving that a reduction in process errors does not automatically lead to healthier patients. That remains the next, even harder, challenge.
The evidence from the field demands a new standard of care. The FDA should adapt its premarket submission process for medical software, requiring a formal “implementation and ethics playbook” as a condition of approval. This playbook must move beyond the algorithm itself to codify the safety of the entire system of care. First, it must mandate an equity impact assessment, requiring vendors to submit data on the tool’s performance across demographic subgroups with a clear plan to mitigate identified biases. Second, it must require a workflow integration plan, with evidence-based protocols for training clinicians and embedding the tool in a live environment. Finally, it must establish a post-market monitoring plan that contractually obligates both vendors and health systems to track real-world performance and report AI-related adverse events.
With U.S. health systems investing billions in AI platforms today, we must remember the hardest work of this revolution won’t happen in a lab or a legislature, but in the clinic. And the lessons learned in Nairobi may be the key to unlocking AI’s true potential for health care everywhere.
Javaid Iqbal Sofi is a doctoral researcher at Virginia Tech specializing in artificial intelligence and health care.



