Copyright arjun
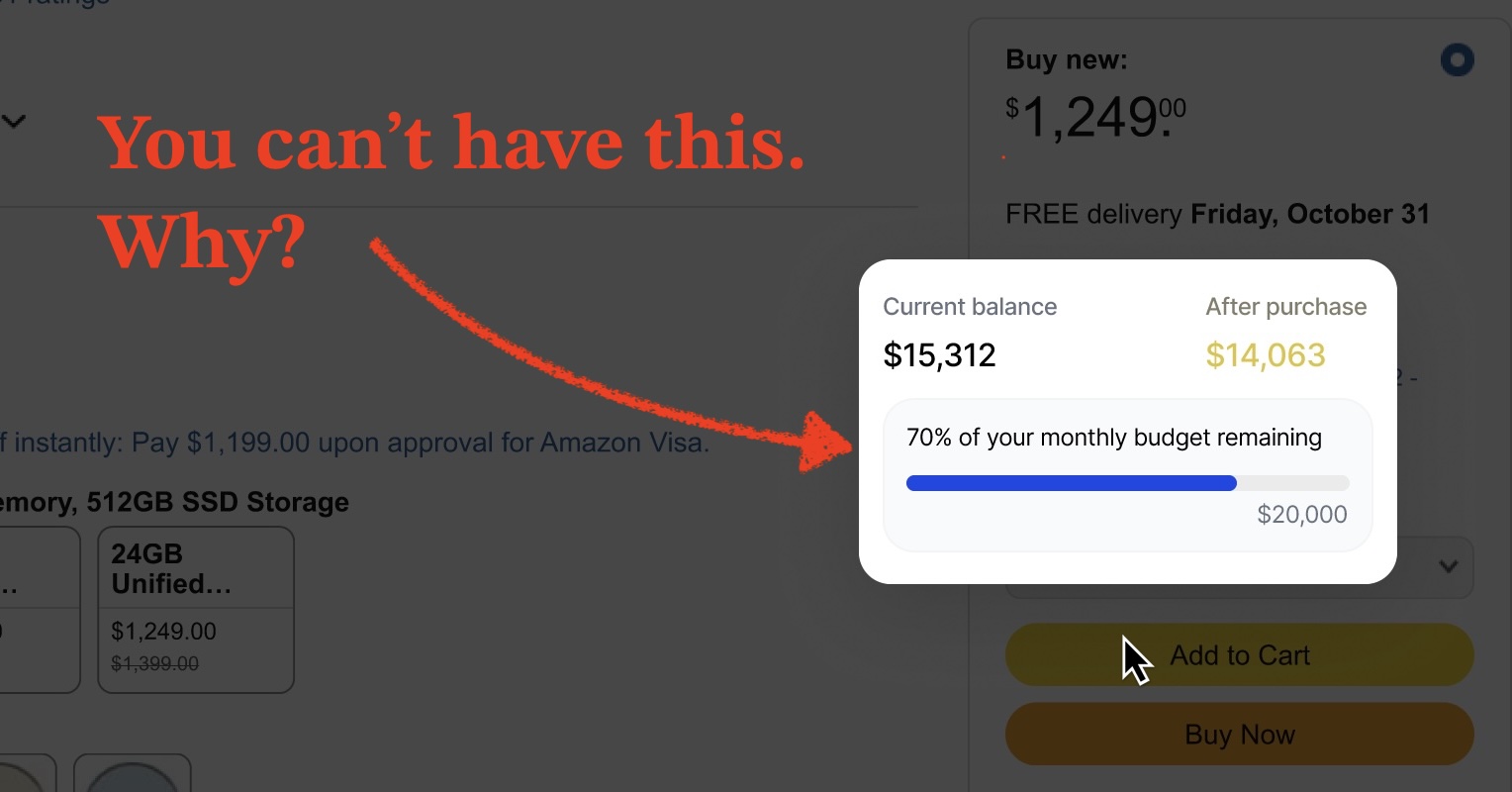
Let the little guys in: Towards a context sharing runtime for the personalised web It’s easier than ever to build small tools. Npm, with 63 billion javascript package downloads in the last week, is a great example of the magic that happens when we can easily fork, share, find, use & compose small tools. It’s also a great example of what it’s missing - it’s hard to trust. Would you trust a new little wrapper or package with all of your bank statements, emails, and ChatGPT history? Today, context is king, and OAuth dialogs are not enough to enable world-wide-web like participation in it. Here’s another idea: Instead of tightly controlling which applications have access to data, we need to control where applications can send it. And in that (attestable) image, a new runtime environment is being forged. Not by me, but I buy into it, and I write this hoping that you might too. Onto the first premise: We’re far from realising the potential of computing To really appreciate that potential, let’s imagine what it might feel like to have realised it. Here’s one handle for your imagination: Imagine if ChatGPT worked perfectly, connected to everything, and knew everything about you. Of course, you have to use your imagination there. ChatGPT is far from perfect. And…it never will be. In terms of sheer LLM horsepower, its ability to benefit from more parameters, and more thinking tokens, to think better and make up stuff less - we seem to be plateauing. As was the case for human beings ~300,000 years ago, the economics for making the brain bigger has basically stopped making sense. So here’s the second handle for your imagination. Think of the last app you used. You have it? Great. Now imagine you could in an instant, transform that app in any way you could imagine, to be better for you. It’s quite a thing to think about. It is fun, so I would recommend it if you can spare some brain. Type your app here to seed some ideas. For me, it was my Banking app. Here are some features I’d want: As above, I want my banking app to insert a little expandable badge beside every “pay” button in my web browser, where it tells me how my current cart or purchase is going to affect my budget or balance. This seems like obviously good UX. In games, I’ve never seen a shop interface that doesn’t show you your remaining cash balance - imagine how weird and bad it would be if you only got a notification after the fact. I want to read a couple sentence summary each month that describes how that month’s gone, with respect to my long term financial goals - and any interesting spending trends that have emerged. I want the ability to ask my bank things. For example: “how much did my cost of living change after moving to cape town?” or: “since I started seeing a dietician last year, how has that affected my spend on food?” or: “how much has my padel habit cost me?” The features you’d want, might differ a lot! For example, maybe you’re better than me at budgeting and have different categories that you want to classify, by linking bank statement line items with the contents of order breakdowns in your email. The point is - the ceiling is high, and we are a long way from it. Why aren’t we further along? Well, to meet all your unmet computing needs, you need a bunch more code, right? Given how hard it’s been to write code, we’ve largely outsourced the writing of it to a group of experts, within sprawling software companies, who are doing their best to Eat the World, with a side of Our Data, but who will never get around to their P3 backlog. I don’t think my banking app will give me those features, ever. And it’s not just the low priority stuff that companies are reticent to build. We have different incentives to companies Where our needs as a user intersect well with the making of profits…we are extremely well served. The size of this intersection is basically the extent of product-market fit. Companies tend to be amazing at: “Make it convenient for me to buy my first thing…and what else can you conveniently bundle in?” Some needs are ignored - because code-writing capacity is finite, and pandering to niche user needs violates the pareto principle. Hotels will jump to put a mini-bar inside your room, but if that’s the only place you can get snacks, you’ll never have wasabi peas. Some needs are actively suppressed: "Make it easy for me to opt out…from your service, from a part of your service, or just from consuming too much”. We don’t have to rely on companies to write code We already rely a lot on open source for our most crucial code - at the heart of our operating systems. For example, here is the source code of Android, which is almost 200 million lines of code, and which stands on the shoulders of other open source projects like Linux (which runs most computers in the Cloud). Most linux development today is funded via for-profit companies, who benefit from Linux meeting their or their customers needs. But the first version was made by one dude to meet his own needs, who posted it on a forum. Today, facilitated by LLM’s, many more people can write little scripts to meet their own needs. Via open source, that code can be cleaned up and grow to meet bigger needs, for bigger audiences. We can also make little edits to the code to fit our own needs. But open source software is often outcompeted by closed source software. There’s a reason why people use MS office or Google to make a powerpoint presentation, and not the many attempts at open source alternatives. Sometimes, the polish required for these products is boring and difficult. Open source software is good for interesting things. Vibe coding is good for small things. So ideally, we want to be able to take code from all 3 places and combine them, via small wrappers, into more need-meeting, tailor-made software. But code is only as useful as the information it has access to. And so access to information has become the limiting reagent in our computing. This is especially the case with the new capabilities we have from LLM’s, to understand the depth of our own context and provide a whole new level of output tailoring. Most of our data is sitting inside a few companies Remember when we used to call Applications “Programs”? Back then, they were just executable code that we’d run on our own computer. Then we started owning multiple computers (including a pocket-sized one!), the Cloud formed, and javascript gave us web applications. So what started as outsourcing code, became outsourcing the actual computing, and most of our data storage, to companies, who could offer the convenience and profitability of a 1-stop-computing-shop. Today’s output becomes tomorrow’s input! So that data grows and grows, inside the same handful of big companies. It seems to work for us too. We prefer a handful of companies - because the fewer apps that have our data, the less exposed we feel. We prefer big companies - because there is safety in numbers. While anti-monopolistic regulation encourages better access to that data…that can only move the market so much. Trust is our computing bottleneck While it’s possible for my bank to implement these features, it’s probably not going to get them to me any time in the next few years (despite all the “AI enablement” and “agentic transformation” going on there lol). It’s actually also possible for these features to be coded up and bolted on, without needing anything from the bank. But it’s too much work for me to code for myself - probably more work than me just looking at my own bank statements. If someone else made a product (that I trusted), I’d pay for it. If there was an open source product, that was easy to use (that I trusted), I would use it. I might even write a compatibility layer for my own South African bank’s statements. I’m open to having it done via integration with ChatGPT too - using their new apps, which could integrate with a new web app and its associated browser extension, to enable these features. But - it doesn’t exist. And the fundamental reason why… is a lack of trust. The new app would need direct access to your bank statements, emails, and chatbot history, and the content of every page you visit on your browser. It is way too hard for an upstart, even with a community behind them, to command the requisite trust. Let’s not be hand-wavey about it - and be more precise what this web app would need to be entrusted to do. (Expand to see why / how) Our patterns for computing with sensitive data make this unfeasible. Sometimes, like with ChatGPT conversations, we don’t have a key to the big company vaults where we keep our data safe. And even when there is access via key, like with gmail, we must be very discerning before clicking “yes” on an OAuth Dialog; minting a new key for that little banking add-on is quite a big risk. Because once access is granted, it can never really be revoked. In the unlikely event that you do remember to change the locks after you retire the add-on, it could still retain your data. Because when the add-on has a key to your vault - even read-only access, it is impossible to know what they’ll do with the data inside it. They can copy it. They can share it. They can sell it. Yes, some of that’s illegal. But possession is 9/10ths of the law, and they have possession of our data. The courts are too weak to meaningfully enforce what web apps do, world-wide. And the world-wideness of the web so useful, so formidable, and so precious; it’s given us 4 billion websites, many of them created by The Little Guys. In the era of LLM’s and of a hyper-personalised private web, we need to find a way for The Little Guys to be trusted enough with our data, to do their magic. Enforcing conditions is better than handing out keys Instead of choosing who to trust unconditionally with our data…why don’t we introduced a few conditions? With the right conditions, we can lower the bar enough to be open to the public, and all the well intentioned Little Guys. We need a runtime environment with right conditions. The internet already got this far, via a well selected runtime environment: the browser’s javascript engine. Because of it, you can click a link, without thinking twice, and run code written by who-knows-who from who-knows-where on the world-wide-web, on your own personal computer, which has all kinds of sensitive information on it. We need to add another runtime environment, with the right conditions. All your data should be moved into that runtime environment - so there is a well organised buffet available to any program you elect to click on. What are the right conditions? There is only one. You are not allowed to transmit or store my sensitive information anywhere (unless I give my consent). Under this condition, sensitive information taints other information, as if it’s radioactive. Any other information it affects becomes sensitive itself, whether it’s an intermediate variable or a final output. Isn’t that too restrictive? Most code today is riddled with network requests. How can code shared with us be useful without them? Where is it supposed to send its output? The code can still make network requests; it just can’t include sensitive data inside those network requests. And it can still derive outputs, and store the outputs…within the runtime environment, which has its own encrypted database. That output, like all other sensitive information, can be decrypted by and revealed to the authenticated user, in any custom format. That format could be a web app. It could even be browser overlay on amazon.com…in a very clear, ringfenced way. How do we enforce the conditions? “Consent” isn’t some flaccid banner blocking half the landing page; it must be demonstrably impossible to circumvent. To do this, we need to invoke two fairly low-key computing patterns First, we need a reliable way to tell which information has been tainted as sensitive. For that, we turn to the field of Information flow, where there are well established mechanisms to evaluate the taint, in modern languages like javascript. Then, we need a publicly verifiable proof that the runtime environment housing the information and running the code is actually enforcing the conditions as it promises - no more, no less, no different. Open sourcing the runtime environment is insufficient proof. For this, we need remote attestation, which can be performed within secure compute environments on most modern clouds. How do we make this happen? For this way of computing to gain any relevance, there needs to be a compelling enough sell to enough users. That seems really, really hard. Whatever the path is, I don’t see it clearly, but it seems to need to trace through two rough milestones. 1. An active community of technical users hacking away in it Those in it might say: “I really buy into the principles of this thing. And it seems useful - look what that person made on it! It seems like a web version of claude code + skills + marketplace, but with an encrypted database, and permissions that let you feel safe using yolo mode. I’m going to try it.” 2. A breakout to heavy users of ChatGPT (et al), with a polished, managed product At this juncture, a product manager type, for example, might say: “Oh, wow, I see how this personalised web OS thing would be useful. Let me get out my credit card, bring all my data onto this thing, and try some of these plugins”. Here are some questions that linger for me: What should the value proposition of the polished, managed product be - and what might it replace (ChatGPT / Notion / Chrome / Tampermonkey)? Can you sell the long tail of features, as a killer feature? How might we aim smaller - should the first step be a standalone service that makes it vercel-easy to serve out of attestable images? How should schema sharing interleave with code sharing, to permit extensibility? What can we augment or transfer from Claude code - given what can already be hacked together there? Is taint tracking watertight enough? How different will runtime compatible code need to be, and what effect will that have on ease of writing/generating? Can/should people be financially incentivised to create useful programs to run in this environment? How can the environment permit sensitive data to leave, at the user’s behest, with graceful UX? How might a browser safely delineate what UI elements are generated from what code? One thing is clear: It’s going to take a community It seems to be forming around Alex Komoroske’s public benefit corp, common.tools…which is where the central idea of an attestable exfiltration proof runtime environment above comes from. After bumping against the trust problem myself, I signed up to the waitlist, which spawned a few really interesting conversations. Here's hoping there are a few more in the comments section! 😀



